Your AI-generated code works. It's probably not production ready.
Shipping features with Claude Code or Cursor is fast now. Getting that code to hold up in production is a separate problem entirely. AI reduces implementation time. It does not produce production engineering.
I went through 8 AI-generated production apps. They all had roughly the same issues:
- Supabase RLS misconfigured
- secrets sitting in the codebase
- no rate limiting, no caching
- bad data structures
- components re-rendering constantly
- AI features open to prompt injection and RAG attacks
- basically no tests around anything important
Most of them worked. Hardly any were production ready.
A year ago, writing code was the bottleneck. Now it’s reviewing and hardening what got generated. That’s a different skill, and most teams aren’t there yet.
The reason this keeps happening: AI is excellent at extending local patterns. It’s much worse at understanding long-term system boundaries, scaling behavior, and operational risk. It generates code that looks right in isolation and breaks under real conditions.
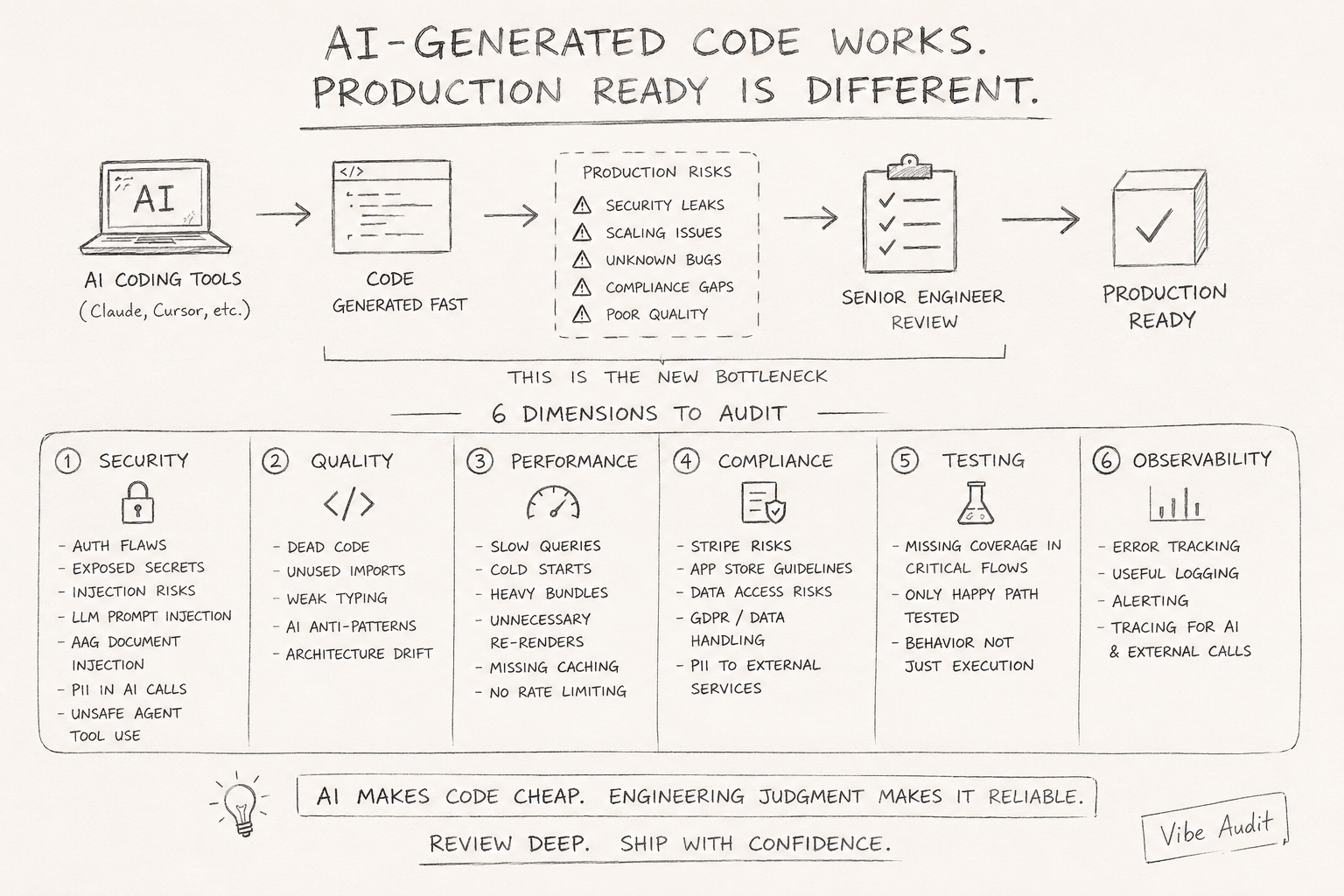
Six things I look at before calling AI-generated code production ready.
Security
This is where things go quietly wrong. The code compiles, tests pass, and then someone finds a misconfigured auth check six months later.
- Auth flows: does every protected route actually verify the session? Are role checks on the server, not just the client?
- Exposed secrets: API keys in frontend code,
.envvalues hardcoded as fallbacks, secrets logged during error handling - Injection risks: SQL, command, and path injection in any user-controlled inputs
- LLM prompt injection: if your app passes user input into an AI prompt, can a user rewrite what the AI does?
- RAG document injection: can a user upload a document that manipulates your AI’s behavior?
Quality
Happy path works fine. The edges are where it falls apart.
- Dead code and unused imports — AI generates confidently, including things it never wires up
- Weak typing:
anyused to paper over uncertainty, missing null checks, unsafe type assertions - Anti-patterns: misused hooks, unnecessary useEffects, logic in the wrong layer
- Architecture drift: after 50 prompts, does the codebase still follow the same conventions it started with?
Performance
AI-generated code tends to duplicate logic instead of abstracting correctly, miss caching layers entirely, and generate DB access patterns that work fine in development and fall apart under load.
- Slow queries: missing indexes, N+1 patterns, fetching more columns than the page needs
- Cold starts: heavy dependencies, unoptimized bundles, serverless functions loading too much on init
- Render cascades: components re-rendering on every state change because nothing is memoized
- Heavy bundles: entire libraries pulled in at the top level when one function was needed
Compliance
Some of this is stack-specific. PII handling isn’t.
- Payment flows: are Stripe webhooks handled correctly? Any card data stored that shouldn’t be?
- App Store: are in-app purchases routed right? Anything that’ll get the app rejected on review?
- Data handling: GDPR basics — deletion, consent, data residency for EU users
- PII and external APIs: are you sending user data to an AI API you haven’t agreed to share it with?
Testing
There are usually tests. They usually test the wrong things.
- Critical paths: auth, payments, data writes — the flows that actually hurt users when they fail
- Are tests checking behavior, or just that the function runs without throwing?
- Are edge cases there, or just the happy path the AI was given in the prompt?
Observability
Most AI-generated codebases have none. Everything’s fine locally. Then it breaks in production and there’s nothing to look at.
- Error tracking: are exceptions being captured, or swallowed silently?
- Logging: structured and useful, or just
console.logstatements scattered around? - Alerting: do you find out when something breaks, or do users tell you?
- Tracing: for AI calls and external APIs, can you follow a request end to end?
Most teams are treating code generation and code review as the same problem. They’re not. The faster teams ship with AI, the faster review debt accumulates — and most teams have no process for it yet.
That’s why I built Vibe Audit. It runs this audit automatically across your codebase and surfaces production risks before they become incidents. GitHub
Ran it on a real app. This is what came back.
